💡
[한빛미디어]Spark 완전가이드 를 보며 정리한 내용임.
* 서적구매 : https://hanbit.co.kr/store/books/look.php?p_code=B6709029941
💡
Spark에서 지원하는
조인타입, 사용법, 내부 동작 방식 들을 다루는 챕터
#python3
DF.join( JoinDF , JoinExpression, (joinType) )
- JoinDF : 조인 대상
- JoinExpression : 조인 표현식(조건)
- joinType : 조인 타입( 생략가능 / defaultValue : inner )
8.1 조인 표현식
- 왼쪽과 오른쪽 데이터셋에 있는 하나 이상의 키값을 비교하고, 결합하는 조인표현식 사용
- 키가 없는 로우는 조인에 포함 시키지 않음.
8.2 조인 타입
- 내부조인 (inner join) : 왼쪽과 오른쪽 데이터셋에 키가 있는 로우 유지
- 외부조인 (outer join) : 왼쪽이나 오른쪽 데이터셋에 키가 있는 로우 유지
- 왼쪽 외부조인 (left outer join) : 왼쪽 데이터 셋에 키가 있는 로우 유지
- 오른쪽 외부 조인 (right outer join) : 오른쪽 데이터셋에 키가 있는 로우 유지
- 왼족 세미 조인 (left semi join) : 왼쪽 데이터셋의 키가 오른쪽 데이터셋에 있는 경우에는 키가 일치하는 왼쪽 데이터셋만 유지
- 왼족 안티 조인 (left anti join) : 왼쪽 데이터셋의 키가 오른쪽 데이터셋에 없는 경우에는 키가 일치하지 않는 왼쪽 데이터셋만 유지
- 자연조인 (natural join ) : 두 데이터셋에서 동일한 이릉믈 가진 컬럼을 암시적(implicit)으로 결합하는 조인을 수행
- 교차 조인 (cross join ) 또은 카테시안 조인(Catesian join) : 왼쪽 데이터셋의 모든 로우와 오른쪽 데이터셋의 모든 로우를 조합.
- 테스트를 위한 코드
person = spark.createDataFrame([ (0, "Bill Chambers", 0, [100]), (1, "mateil Zaharia", 1, [500,250,100]), (2, "Michael Armbrust", 1, [250,100])])\ .toDF("id", "name", "graduate_program", "spark_status") graduateProgram = spark.createDataFrame([ (0, "Master", "School of Information", "UC Berkeley"), (2, "Master","EECS", "UC Berkeley"), (1, "Ph.D.", "EECS", "UC Berkeley")])\ .toDF("id", "degree", " department", "school") sparkStatus = spark.createDataFrame([ (500, " Vice President"), (250, "PMC Member"), (100, "Contributor")])\ .toDF("id", "status") graduateProgram
- persson

- graduateProgram

- sparkStatus

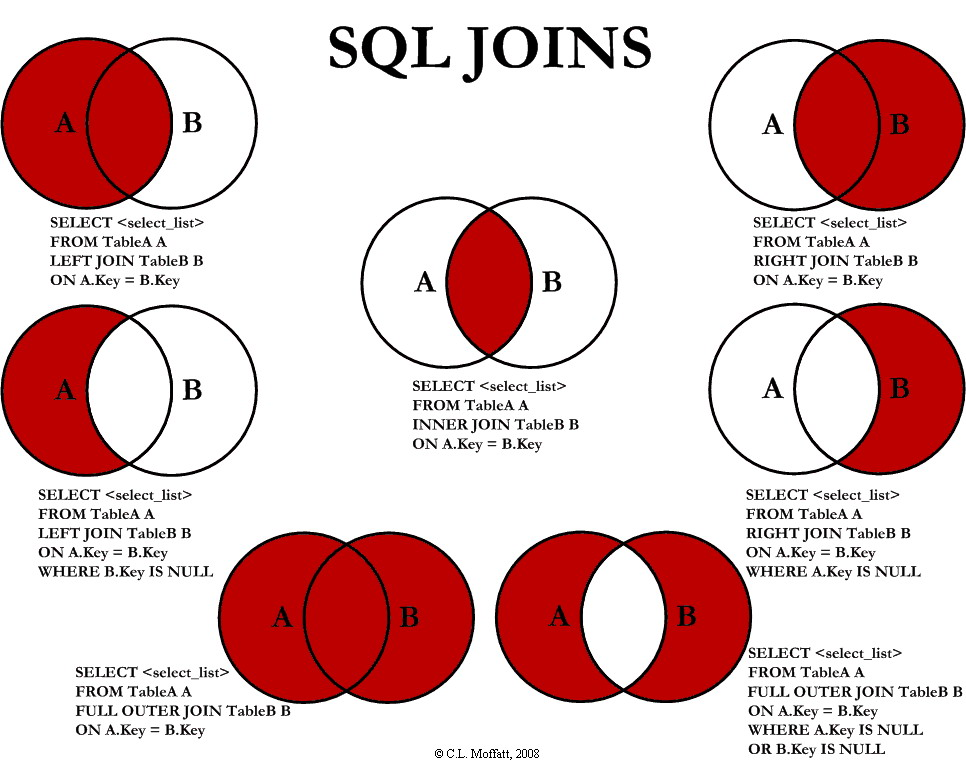
8.3 내부조인(Inner Join)
joinExpression = person["graduate_program"] == graduateProgram['id']
person.join( graduateProgram , joinExpression , "inner"(생략가능) )
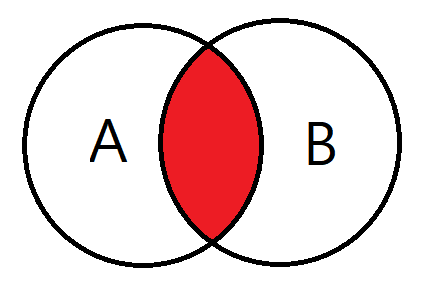
8.4 외부 조인
- 일치로우가 없을경우 해당위치에 null을 삽입함.
joinType = "outer"
joinExpression = person["graduate_program"] == graduateProgram['id']
person.join(graduateProgram , joinExpression, joinType ).show()
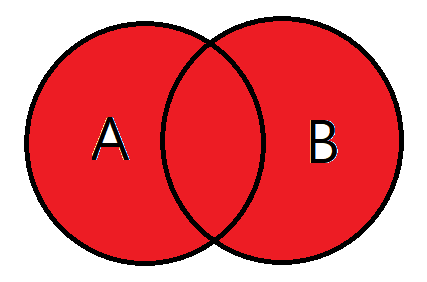
8.5 왼쪽 외부 조인
joinType = "left_outer"
joinExpression = person["graduate_program"] == graduateProgram['id']
person.join(graduateProgram , joinExpression, joinType ).show()
# graduateProgram.join(person , joinExpression, joinType ).show()
8.6 오른쪽 외부 조인
joinType = "right_outer"
joinExpression = person["graduate_program"] == graduateProgram['id']
person.join(graduateProgram , joinExpression, joinType ).show()
# graduateProgram.join(person , joinExpression, joinType ).show()
8.7 왼쪽 세미 조인 ( Left Semi Join)
- 기존 조인기능과 달리 Dafatrame의 필터 기능으로 볼 수 있음.
- 조인 결과값에 TargetDF에 해당하는 값은 포함하지 않음
joinType = "left_semi"
joinExpression = person["graduate_program"] == graduateProgram['id']
person.join( graduateProgram , joinExpression, joinType ).show()
# ouput(Schema/Data) : Person
# 검색조건 : joinExpression
8.8 왼쪽 안티 조인 (Left Anti Join)
- 세미 조인의 반대 개념
- SQL의 Not In과 같은 개념으로 볼 수 있음
joinType = "left_anti"
joinExpression = person["graduate_program"] == graduateProgram['id']
graduateProgram.join(person , joinExpression, joinType ).show()
# graduateProgram.join(person , joinExpression, joinType ).show()

8.9 자연 조인
- 내부적으로 컬럼키를 추측하여 Join함. ( 매우 위험해보임 사용하는것은 지양 하기 )
8.10 교차 조인(카테시안 조인) // Cross Join, Cartesian Join
- 조건절을 따로 명시하지않고, 모든 경우의 수를 생성하는 Join 방식
* (경고)대량의 데이터가 생성되기 때문에 꼭 필요한 경우에만 사용하기
*
spark.ssql.crossJoin.enable속성값으로 사용 여부 설정 가능
- (DF A 로우 수) X (DF B 로우 수) 개의 로우값을 생성함.
- crossJoin 메서드를 사용 가능

graduateProgram.crossJoin(person).show()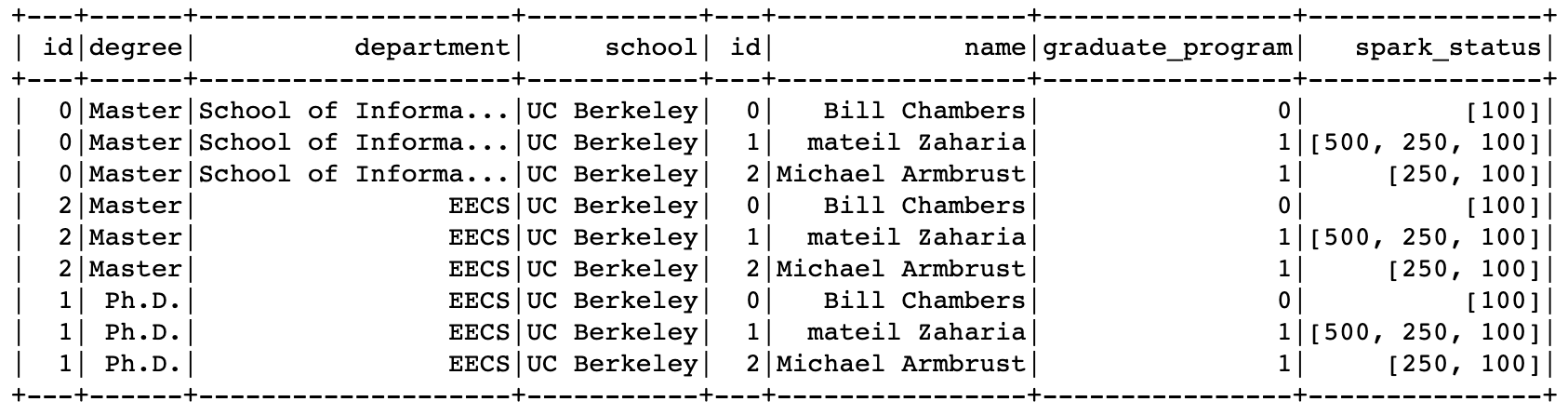
책 예제 (내용확인 하기)
joinType = "cross" joinExpression = person["graduate_program"] == graduateProgram['id'] graduateProgram.join(person , joinExpression, joinType).show()
8.11 조인 사용 시 문제점
8.11.1 복합 데이터 타입의 조인
- 불리언을 반환하는 모든 표현식은 조인표현식으로 간주할 수 있음
person.withColumnRenamed("id","personId")\
.join(sparkStatus, expr("array_contains(spark_status, id)")).show()
쥬스 Q
# 문법상 Perosn의 spark_satus에, sparkStatus의 id의 존재여부를 확인한거같은데.. 이게맞나? * 예상시나리오 .join실행시 crossjoin(모든경우의수 생성) , 거기서 조인표현식의 값을 추출?- step1) join
person.withColumnRenamed("id","personId")\ .join(sparkStatus)\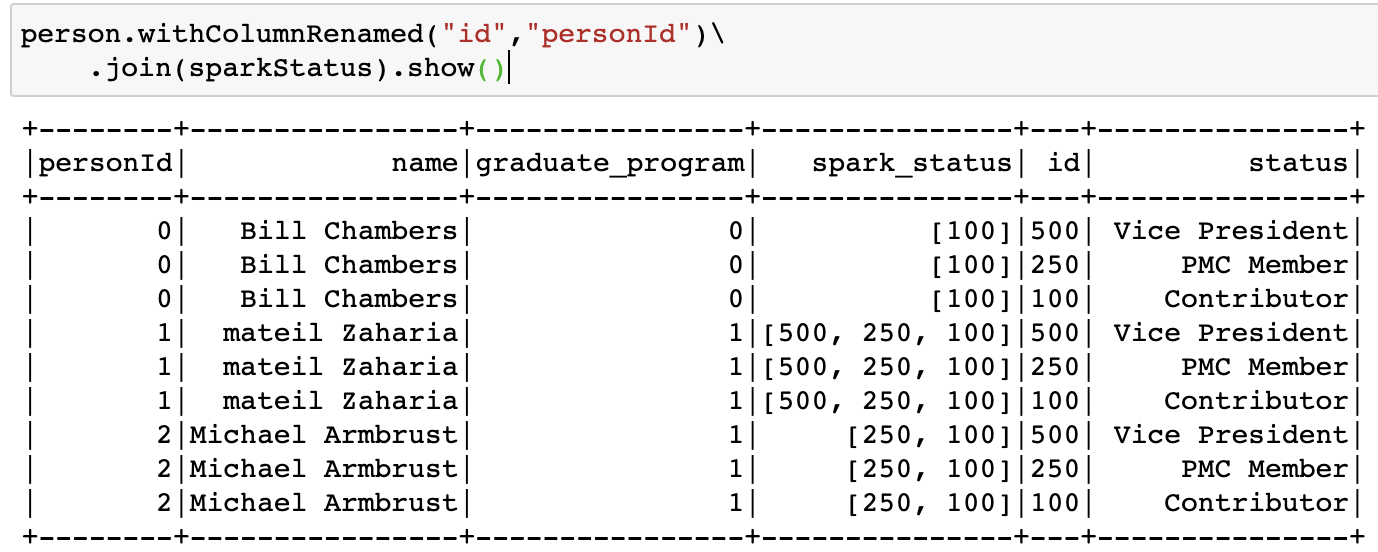
- step2) 조건식
person.withColumnRenamed("id","personId")\ .join(sparkStatus)\ .where(array_contains("spark_status", col("id")))\ .show()
- step1) join
8.11.2 중복 컬럼명 처리
- 하나의 DF에 동일한 컬럼명을 가지는 컬럼이 존재할 경우 처리방법💡일반적으로 아래와 같은 에러가 발생함
AnalysisException: Reference 'id' is ambiguous, could be: id, id.#예제 joinExpr = person["id"] == sparkStatus['id'] person\ .join(sparkStatus,joinExpr)\ .where(array_contains("spark_status", col("id")))\ .show()
책 예제(실행잘됨)
graduateDupe = graduateProgram.withColumnRenamed("id", "graduate_program") joinExpr = graduateDupe["graduate_program"] == person['graduate_program'] person.join(graduateDupe,joinExpr).show()
- case1) 다른 조인표현식 사용
- 불리언 표현식을 문자열이나 시퀀스 타입으로 변경
- case2) 조인 후 컬럼 제거
- case3) 조인전 컬럼명 변경
8.12 스파크의 조인 수행 방식
8.12.1 네트워크 통신 전략
- 셔플 조인
- 전체 노드간 통신
- 브로드캐스트 조인
- 단일 워커노드의 메모리크기로 충분한 연산이 가능할 경우 적합
- 전체 노드간 통신 → 초기 통신이후 추가 통신 발생 X
💡
일반적인 작은테이블간 통신시 스파크가 조인 방식을 결정하도록 내버려두는게 효율적
8.13 정리
기타
- 이미지출처
Uploaded by N2T