💡
[한빛미디어]Spark 완전가이드 를 보며 정리한 내용임.
* 서적구매 : https://hanbit.co.kr/store/books/look.php?p_code=B6709029941
5. 구조적 API 기본 연산 (CHAPTER 5)
- Dataframe 의 구성요소 : 레코드, 컬럼 으로 구성 (Row타입)
#python3
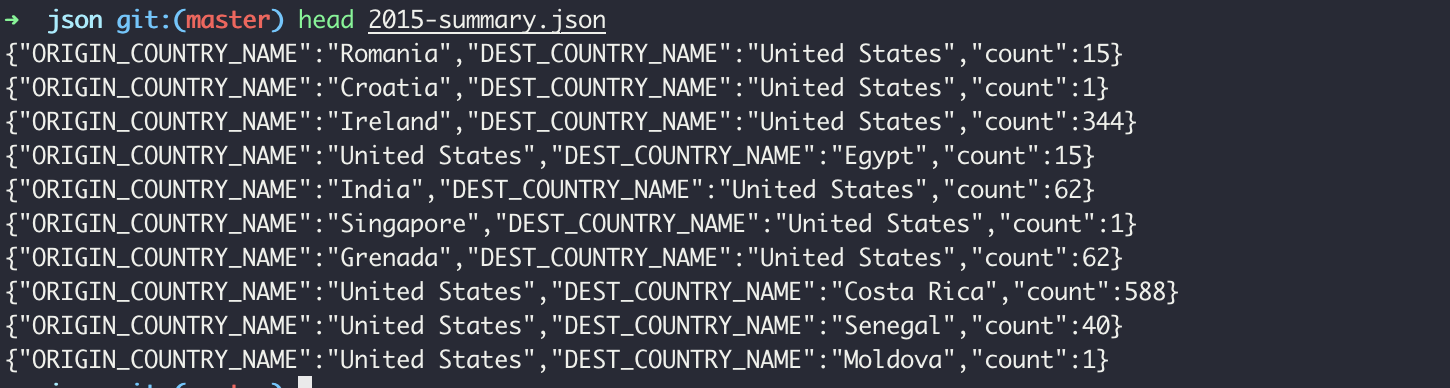
df = spark.read.format("json").load("/Users/jinsu/study/spark/Spark-The-Definitive-Guide/data/flight-data/json/2015-summary.json")
df.printSchema()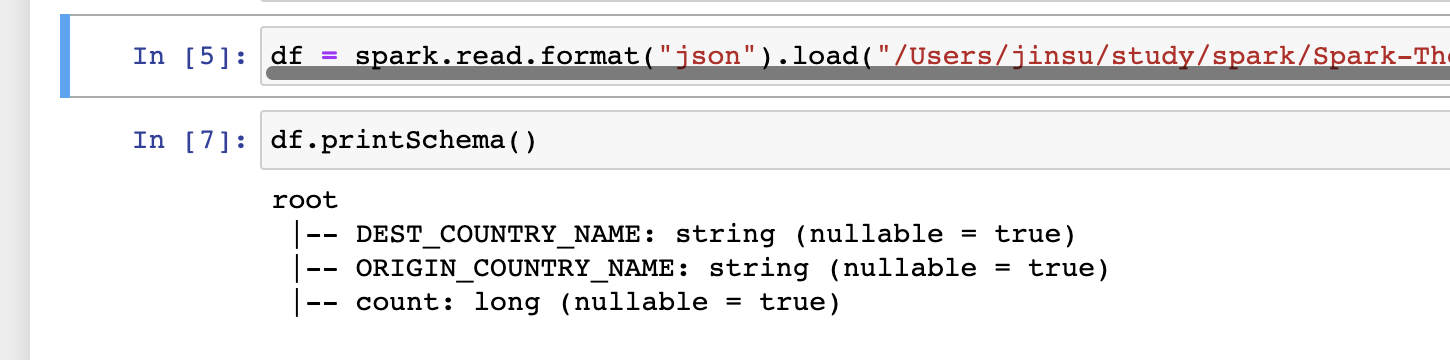
5.1 스키마
- Dataframe의 컬럼명과, 타입을 정의함.
- 소스에서 스키마를 얻거나, 직접 정의가 가능 * CSV,JSON등의 소스를 사용할 경우 스키마를 직접 정의하여 주지 않으면, 스키마 추론과정에서 타입이 변경될 수 있으니 주의 필요
- Case1) 스키마 추출
#python3 spark.read.format("json") .load("/Users/jinsu/study/spark/Spark-The-Definitive-Guide/data/flight-data/json/2015-summary.json") .schema➡️OutputStructType(List(StructField(DEST_COUNTRY_NAME,StringType,true), StructField(ORIGIN_COUNTRY_NAME,StringType,true), StructField(count,LongType,true)))
- case2) 스키마 선언
- 데이터를 불러올때 사전에 정의한 스키마를 사용할 수 있음
#python3 from pyspark.sql.types import StructField, StructType, StringType, LongType myManualSchema = StructType([ StructField("DEST_COUNTRY_NAME", StringType(), True), StructField("ORIGIN_COUNTRY_NAME", StringType(), True), StructField("count", LongType(), False, metadata={"hello":"world"}) ]) df = spark.read.format("json") .schema(myManualSchema) .load("/Users/jinsu/study/spark/Spark-The-Definitive-Guide/data/flight-data/json/2015-summary.json")
5.2 컬럼과 표현식
컬럼
- 스파크의 컬럼은 스프레드시트, R의 dataframe, Pandas의 DataFrame 컬럼과 유사
- 표현식으로 Dataframe의 컬럼을 선택,조작,제거 합니다.
- Dataframe → Row → Column 단계적 접근이 필요함.
- col, Column 함수를 사용하여 컬럼 생성 —> Q: 두 함수의 차이점은 무엇일까?
#python3
from pyspark.sql.functions import col, column
col("jinsuTest")
column("JuiceTest")
- 명시적 컬럼
#python3
df["count"]
## Scala == df.col("count")
표현식
- Datafram 레코드의 여러 값들에 대한 트랜스포메이션 집합
- 여러 컬럼명을 입력으로 받아 식별하고, ‘단일 값'을 만들기 위해 레코드에 표현식을 적용
#python3
from pyspark.sql.functions import expr
#아래 3개 코드는 모두 같은 트랜스포메이션 작업을 하는 코드임
expr("someCol - 5")
col("someCol") - 5
expr("someCol") - 5
- 컬럼은 단지 표현식일 뿐이다.
- 컬럼과 컬럼의 트랜스포메이션은 파싱된 표현식과 동일한 논리적 실행계획으로 컴파일됨
DataFrame 컬럼에 접근
- Dataframe의 columns 속성으로 컬럼의 접근
spark.read.format("json").load("/Users/jinsu/study/spark/Spark-The-Definitive-Guide/data/flight-data/json/2015-summary.json").columns
5.3 레코드와 로우
- DataFrame의 각 로우는 하나의 레코드 ( 레코드 == 로우 )
- 로우 객체는 내부에 바이트 배열을 가짐 → 바이트객체는 컬럼표현식으로만 다룰수 있어, 사용자에게 절대 노출되지 않음
df.first()
# 첫행 보여줌
로우
- Row자체는 스키마를 가지지 않기에 Datafrmae의 스키마와 같은 순서대로 명시
- 로우생성 예시
# pytho3 from pyspark.sql import Row myrow = Row("Hello", None, 1, False) myrow >>> <Row('Hello', None, 1, False)> myrow[0] >>> 'Hello'
5.4 DataFrame의 트랜스 포메이션
5.4.1 Dataframe
- 로우,컬럼 추가, 삭제, 변환
- 컬럼값 기준 순서변경
- 예시1 ( 데이터 불러와 사용 )
#python3 df = spark.read.format("json").load("/Users/jinsu/study/spark/Spark-The-Definitive-Guide/data/flight-data/json/2015-summary.json") df.createOrReplaceTempView("dfTable")
- 예시2 ( 신규 생성 )
from pyspark.sql import Row myManualSchema = StructType([ StructField("some", StringType(), True), StructField("col", StringType(), True), StructField("names", LongType(), False) ]) myRow = Row("Hello",None, 1) myDf = spark.createDataFrame([myRow], myManualSchema) myDf.show()

5.4.2 Select와 selectExpr
- Select와 selectExpr를 사용하여 SQL을 실행하는것처럼 DF에서도 SQL을 사용할수 있음 → Q. 이거랑 SparkQL이랑 같은건가 ?
- select
# python3 df.select("DEST_COUNTRY_NAME").show(2) ## select DEST_COUNTRY_NAME from df limit 2 와 동일함 df.select("DEST_COUNTRY_NAME", "ORIGIN_COUNTRY_NAME").show(2) ## select DEST_COUNTRY_NAME, ORIGIN_COUNTRY_NAME from df limit 2 와 동일함 df.select( expr("DEST_COUNTRY_NAME AS destination")).show(2) ## select DEST_COUNTRY_NAME as destination from df limit 2 와 동일함 df.select( expr("DEST_COUNTRY_NAME").alias("destination") ).show(2) ## select DEST_COUNTRY_NAME as destination from df limit 2 와 동일함
- 에러가 나는지??
# 에러안남 df.select( col("DEST_COUNTRY_NAME"),"DEST_COUNTRY_NAME" ).show()
- selectExpr
- select 에 expr 함수를 사용함에있어 효율적으로 사용이 가능하도록 selectExpr메서드를 제공함
- DataFrame을 생성하는 복잡한 표현식을 간단하게 만들어주는 도구
#python3 df.selectExpr("DEST_COUNTRY_NAME as test").show(2) ## select DEST_COUNTRY_NAME as destination from df limit 2 와 동일함 df.selectExpr( "*", "(DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME) as withinContry" ).show(2) ## select *, (DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME) as withinContry ## from df limit 2 와 동일함 df.selectExpr( "avg(count)", "count(distinct(DEST_COUNTRY_NAME))" ).show() ## select avg(count), count(distinct(DEST_COUNTRY_NAME)) ## from df
5.4.3 스파크 데이터 타입 변환
- 명시적으로 값을 사용할경우 리터럴을 사용
- 상수값혹은 특정 컬럼의 값과 비교하기 위할떄 주로 사용함
#python3 from pyspark.sql.functions import lit df.select(expr("*"), lit(1).alias("one")).show() # select * , 1 as one from df 와 동일함
5.4.4 컬럼추가(withColumn)
- Dataframe에 신규 컬럼을 추가하는 공식적인 방법은 withColumn 메소드 사용
#python3
df.withColumn("numberOne", lit(1)).show()
# select *, 1 from df 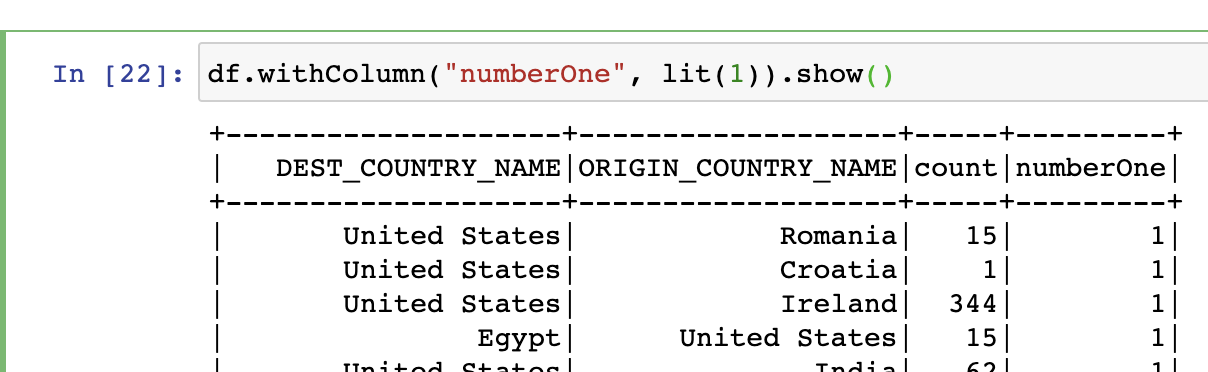
- 예제
#python3
#출발지와 도착지가 같은지여부를 boolean타입으로 표현
df.withColumn("withContry", expr("ORIGIN_COUNTRY_NAME == DEST_COUNTRY_NAME" )).show()
#column변경
df.withColumn("destination",expr("DEST_COUNTRY_NAME")).show()
5.4.5 컬럼명 변경 (withColumnRenamed)
- withColumnRenamed 메서드를 통해 변경 withColumnRenamed(”변경전", ”변경후)
df.withColumnRenamed("DEST_COUNTRY_NAME","rename_DEST_COUNTRY_NAME").show()
5.4.6 예약 문자와 키워드 ( `(백틱) )
- 공백이나 -(하이픈)을 사용할경우 `(백틱)을 사용해야함. (표현식내에서 문제가 됨)
#python3
# withColumn 사용하는 첫번째 인수는 문자열일 괜찮음
dfWithLongColumn = df.withColumn(
"this Long Column-Name",
expr("ORIGIN_COUNTRY_NAME")
)
# 사용가능
dfWithLongColumn.select("this Long Column-Name").show()
# 사용불가
dfWithLongColumn.select(expr("this Long Column-Name")).show()
# 사용가능
dfWithLongColumn.select(expr("`this Long Column-Name`")).show()
# 사용불가
dfWithLongColumn.selectExpr("this Long Column-Name").show()
# 사용가능
dfWithLongColumn.selectExpr("`this Long Column-Name`").show()
5.4.7 대소문자구분 (default = false)
- 기본적으로 spark 는 대소문자 구분을 하지않으나, 아래 명령어(설정)를 통하여 대소문자 구분이 가능하도록 설정 가능
## SQL?
set spark.sql.caseSensitive true
# python3
spark.conf.set('spark.sql.caseSensitive', True)
5.4.8 컬럼 제거하기 (drop)
- Datafrmae 컬럼제거는 drop 메소드를 사용함
#python3
df.drop("DEST_COUNTRY_NAME").show()
df.drop("DEST_COUNTRY_NAME", "count").show()
5.4.9 컬럼의 데이터 타입 변경(cast)
- 형변환 작업 시 cast 병령어 사용
#python3
df.withColumn("count2", expr("count").cast("string"))
5.4.10 로우 필터링 ( filter , where )
- 일반적인 예시 )
#python3 df.filter( col("count") == 15).show() df.where( col("count") == 15).show() # 위 두개 명령어 모두 해당 SQL 과 같은 명령을 수행함 # select * from df where count=15
- AND 조건 사용시 차례대로 필터 적용
df.where( col("count") == 15)\ .where( col("DEST_COUNTRY_NAME") == "United States").show() # select * from df where count=15 AND DEST_COUNTRY_NAME = "United States"
5.4.11 고유한 로우 얻기 ( distinct )
- 고유값 사용 distinct
df.select("ORIGIN_COUNTRY_NAME").distinct().count() # select count(distinct ORIGIN_COUNTRY_NAME) from df
💡
아래 부터는 분석/학습 관련된 분야에서 사용될 것으로 추측됨
일반적인 데이터 ETL 등에서는 사용하지않을거같은데 ...
5.4.12 무작위 샘플 만들기 ( sample )
- 무작위 샘플데이터 생성
- 표본데이터 비율 지정 가능 및 복원추출이나 비복원 추출의 사용여부 지정 가능
#python3 seed = 5 whitReplacement = False fraction = 0.5 df.sample(whitReplacement , fraction , seed ).show()
5.4.13 임의 분할 ( randomSplit)
- Dataframe 을 임의의 크기로 분할 할떄 사용
- 머신러닝 알고리즘 사용할때 학습셋, 검증셋, 테스트 셋을 만들때 사용함
#python3 # 분할 가중치를 함수의 파라미터로 설정해 원본 DataFrame을 서로 다른 데이터를 가진 두개의 Dataframe 으로 나누는 예제 # randomSplit([0.25, 0.75], seed) # 앞의 두개의 숫자는 합이 1이되게 지정하고, seed는 임의의 숫자를 사용함(없어도됨) splitDataframe = df.randomSplit([0.25, 0.75], 1) # splitDataframe[0].count() splitDataframe[1].count()
5.4.14 로우 합치기와 추가하기 ( union )
- Dataframe 은 기본적으로 불변성의 속성을 가지기 때문에 변경이 불가능하며, 추가하기 위해서는 통합(union) 해야 함.
- 통합하는 대상의 스키마와, 컬럼수가 동일해야함.
- 통합시 정렬은 보장 못함.
#python3 schema = df.schema newRows = [ Row("new con","otuher Country", 50000), Row("new con2","otuher Country 3", 10004), ] # parallelizedRows = spark.sparkContext.parallelize(newRows) newDf = spark.createDataFrame(newRows, schema) # newDf = spark.createDataFrame(parallelizedRows, schema) df.union(newDf).where(col("count") > 10000 ).show()
5.4.15 로우 정렬하기 ( sort ,orderBy, sortWithinPartitions )
- sort 와 orderBy 메소드는 같은 방식으로 동작함
- 정렬 기준을 사용할땐 asc, desc함수를 사용함
#python3 df.sort("count").show() df.orderBy("count", "DEST_COUNTRY_NAME").show() df.orderBy(col("count"), col("DEST_COUNTRY_NAME")).show() #정렬 기준을 사용할때 df.orderBy(expr("ORIGIN_COUNTRY_NAME desc")).show() # 예제 에는 있는데 실제론 desc 정렬이 안됨 df.orderBy(expr("count").desc()).show() df.orderBy(expr("count").asc(), expr("DEST_COUNTRY_NAME").desc() ).show()
- asc_nulls_first, asc_nulls_last, desc_nulls_first, desc_nulls_last 메소드를 사용하여 정렬 상태에서 null 표시 기준 지정 가능
- 트랜스포메이션전 성능최적화를 위해 파티션 정렬을 사용하기도함. ( sortWithinPartitions )
#python3 spark.read.format("json").load("/Users/jinsu/study/spark/Spark-The-Definitive-Guide/data/flight-data/json/*-summary.json")\ .sortWithinPartitions("count")
5.5.16 로우수 제한 ( limit )
- limit 사용
df.limit(10).show()
5.4.17 repartition과 coalesce (파티셔닝)
- 컬럼기준 데이터 분할
- repartition메서드 호출 시 전체 데이터 셔플 * 향후 사용할 파티션 수가 현재 파티션 수보다 많거나 컬럼을 기준으로 파티션을 만드는 경우에만 사용해야 함
#python3
df.rdd.getNumPartitions()
df.repartition(5)
# 특저ㅇ 컬럼을 기준으로 자주 필터링 한다면 해당 기준 컬럼으로 파티션 재분배
df.repartition(col("DEST_COUNTRY_NAME"))
# 선택적으로 파티션 수를 지정
df.repartitions(5, col("DEST_COUNTRY_NAME"))
- coalesce 메서드는 셔플하지 않고 파티션 병합
#python3 # 목적지 기준 셔플을 수행해 5개의 파티션으로 나누고, 전체 데이터를 셔플 없이 병합하는 예제 df.repartition(5, col("DEST_COUNTRY_NAME")).coalesce(2)
5.4.18 드라이버로 로우 데이터 수집하기 ( 로컬환경 )
#python3
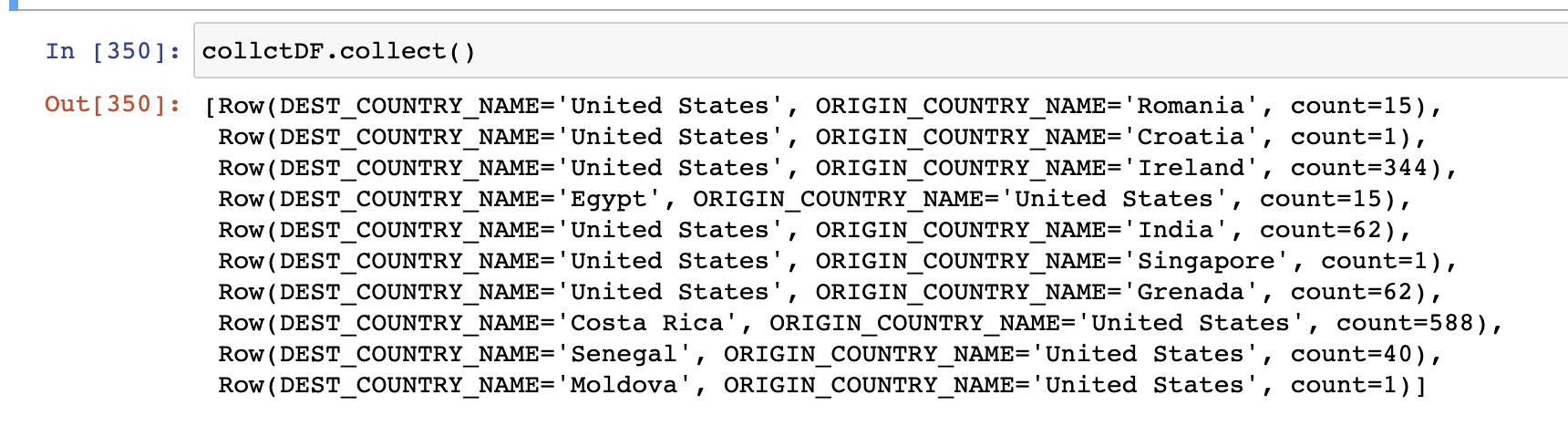
collctDF = df.limit(10)
collctDF.take(5) # 상위 N개의 로우 반환
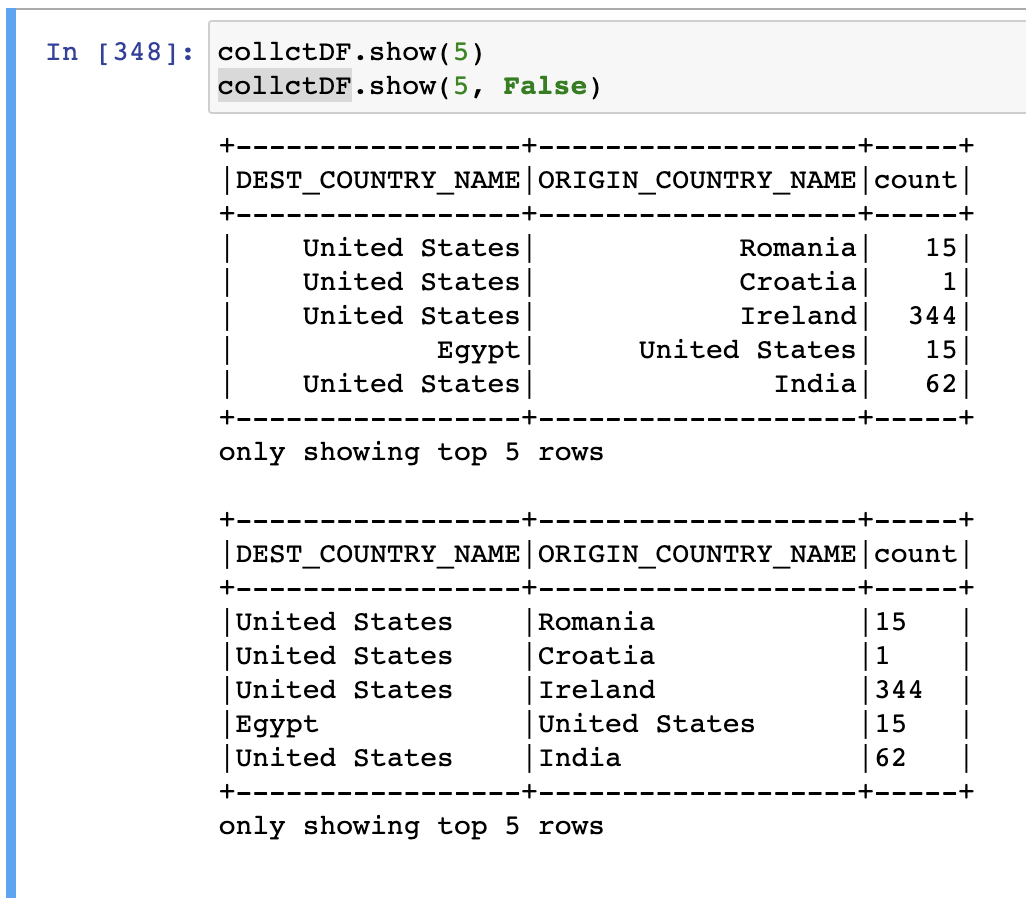
collctDF.show(5) # 로우를 정돈된 형태 출력 (오른쪽정렬)
collctDF.show(5, False) # 왼쪽정렬?
collctDF.collect() # Dataframe의 모든 데이터 - 결과 캡처본

- toLocalItoerator 메서드를 사용하면 모든 파티션의 데이터를 드라이버에 전달
collctDF.toLocalIterator()
- generator 형태
Uploaded by N2T