💡
[한빛미디어]Spark 완전가이드 를 보며 정리한 내용임.
* 서적구매 : https://hanbit.co.kr/store/books/look.php?p_code=B6709029941
💡
Key 나 Group을 지정하고 컬럼을 변환하는 작업에서 사용되는 함수를 집계함수 라고 함.
집계함수에 따라 그룹화된 결과는 RealationalGroupedDataset을 반환함.
- group by , window, grouping set, rollup , cube
- 사용 예제 DF
df = spark.read.format("csv")\ .option("header","true")\ .option("inferSchema","true")\ .load("/Users/jinsu/study/spark/Spark-The-Definitive-Guide/data/retail-data/all/*.csv")\ .coalesce(5)
7.1 집계 함수
- 일반적인 집계함수는
org.apache.spark.sql.functions패키지를 사용함
7.1.1 count
- count ( 액션함수 / 541910 Line ( Header 포함) )
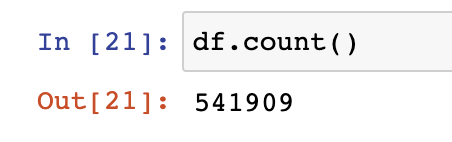

df.select(count("StockCode")).show()
df.select(count("*")).show() ## null값을 가진 row를 포함하여 계산함
# select count(*) from df
7.1.2 countDistinct
- 고유 레코드 수
df.select(countDistinct("StockCode")).show() # select count(discint *) from df
7.1.3 approx_count_distinct ( 근사치 계산 )
- 최대 추정 오류율을 추가 파라미터로 사용함.
- 어느 수준의 정확도를 가지는 근사치 데이터 추출
- countDistinct 보다 빠르게 결과를 반환함.
df.select(approx_count_distinct("StockCode",0.1)).show()
7.1.4 first , last
- 첫번째 Row, 마지막 Row
df.select(first("StockCode"), last("StockCode")).show() # select first(StockCode), last(StockCode) from df
7.1.5 min, max
- 최대값 최소값
df.select(min("Quantity"), max("Quantity")).show() # select min(Quantity), max(Quantity) from df
7.1.6 sum
- 합계
df.select(sum("quantity")).show() ## 숫자 타입 외의 타입을 sum할경우 null을 출력 (실행자체의 오류는 발생하지 않음) ## df.select(sum("Country")).show() << Country 의 경우 String Type 이며, 결과값으로 null을 출력함.
7.1.7 sumDistinct (sum_distinct)
- 고유값의 합계 계산
- spakr 3.2 version에서
sum_distinct가 추가되었음. 링크- sumDistinct 사용시 sum_distinct사용을 권장하는 경고가 발생함 .
df.select(sumDistinct("Quantity")).show() df.select(sum_distinct("Quantity")).show() # 위와 아래 같은 결과를 산출함
- sumDistinct 사용시 sum_distinct사용을 권장하는 경고가 발생함 .
7.1.8 avg , mean
- 전체 합계를 개수만큼 나누는 일반적인 방법 외에 avg함수와, mean을 사용하여 평균값 도출 가능
df.select( count("Quantity").alias("total_transations"), sum("Quantity").alias("total_purchases"), avg("Quantity").alias("avg_purchases"), expr("mean(Quantity)").alias("mean_purchases"))\ .selectExpr( "total_purchases/total_transations", "avg_purchases", "mean_purchases").show()
7.1.9 분산과 표준편차 (variance, stddev )
- 표준분산(var_samp), 표준편차 (stddev_samp)
- 모표준분산(var_pop), 모표준편차(stddev_pop)
df.select( var_pop("Quantity"), var_samp("Quantity"), stddev_pop("Quantity"), stddev_samp("Quantity") ).show()
7.1.10 비대칭도와 첨도 (skewness, kurtosis)
- 데이터의 변곡점 측정
- 비대칭도(skewness) : 평균의 비대칭정도 측정,
- 첨도(kurtosis) : 데이터의 끝부분 측정
df.select(skewness("Quantity"), kurtosis("Quantity")).show()
7.1.11 공분산과 상관관계 (corr, covar_samp, covar_pop)
- 피어슨 상관계수 측정 -1과 1 사이값
df.select( corr("InvoiceNo", "Quantity"), covar_samp("InvoiceNo", "Quantity"), covar_pop("InvoiceNo", "Quantity") ).show()
7.1.12 복합 데이터 타입의 집계 (collect_set , collect_list )
- 컬럼의 값을 리스트나 셋 데이터 타입으로 수집 할 수 있음
df.agg(collect_set("Country"), collect_list("Country")).show()
7.2 그룹화
- 그룹화 2단계 : 하나이상의 컬럼을 그룹화 → 집계연산 수행
- 1단계 : RealationGraoupedDataset반환
- 2단계 : Dataframe 반환
(df.groupBy("InvoiceNo", "CustomerID") # 1단계 .count() # 2단계 ).show()

7.2.1 표현식을 이용한 그룹화
- count를 select구문에 표현식으로 지정하는것보단 agg메서드 사용이 더 좋음.
- agg 메서드는 여러 집계 처리를 한번에 지정할 수 있으며, 집계에 표현식을 사용 할 수 있습니다.
df.groupBy("InvoiceNo").agg( count("Quantity").alias("quan"), expr("count(Quantity)") ).show()

7.2.2 맵을 이용한 그룹화
- 수행할 집계함수를 한줄로 작성하면 여러 컬럼명을 재사용 할 수 있습니다
df.groupBy("InvoiceNo").agg(expr("avg(Quantity)"), expr("stddev_pop(Quantity)")).show()
7.3 윈도우 함수
- spark 지원 윈도우함수 3가지 : 랭크함수, 분석함수, 집계함수
from pyspark.sql.window import Window패키지 추가
- 윈도우함수 테스트 DF생성
dfWithDate = df.withColumn("date", to_date(col("InvoiceDate"), "MM/d/yyyy H:mm")) dfWithDate.createOrReplaceTempView("dfWithDate") dfWithDate.show(2) 💡
💡You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0, or set to CORRECTED and treat it as an invalid datetime string예제대로 실행할경우 에러 발생. 방법1) 아래 설정값 추가spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")방법2) 월,일 날짜 통일시켜주기 dfWithDate = df.withColumn("date", to_date(col("InvoiceDate"), "M/d/yyyy H:mm"))
- 예제-1.1
- 셋팅
windowSpec = (Window .partitionBy("CusstomId","date") # 그룹화 .orderBy(desc("Quantity")) # 파티션정렬 .rowsBetween(Window.unboundedPreceding, Window.currentRow)) maxPurchaseQuantity = max(col("Quantity")).over(windowSpec) purchaseDenseRank = dense_rank().over(windowSpec) purchaseRank = rank().over(windowSpec)
셋팅확인


- 출력
dfWithDate.where("CustomerId IS NOT NULL").orderBy("CustomerId")\ .select( col("CustomerId"), col("date"), col("Quantity"), purchaseRank.alias("purchaseRank"), purchaseDenseRank.alias("purchaseDenseRank"), maxPurchaseQuantity.alias("maxPurchaseQuantity") ).show() --SQL SELECT CustomerId, date, Quantity, rank(Quantity) OVER (PARTITION BY CustomerId, date ORDER BY Quantity DESC NULLS LAST ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as rank, dense_rank(Quantity) OVER (PARTITION BY CustomerId, date ORDER BY Quantity DESC NULLS LAST ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as dRank, max(Quantity) OVER (PARTITION BY CustomerId, date ORDER BY Quantity DESC NULLS LAST ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as maxPurchase FROM dfWithDate WHERE CustomerId IS NOT NULL ORDER BY CustomerId
- 셋팅
7.4 그룹화 셋
- rollup , cube, group 차이점 : (추천)링크
- 여러 집계를 결합하는 저수준 기능
- SQL 문법 : GROUPING SETS 사용
- DF 문법 : 롤업(rollup) 메서드와 큐브(cube)메서드 사용
- 그룹화 셋을 사용하여 Group-by 구문에서 원하는 형태로 집계 생성 가능
- 그룹화셋 테스트 DF 생성
dfNonNull = dfWithDate.drop() dfNonNull.createOrReplaceTempView("dfNonNull")
7.4.1 롤업(rollup)
- group by 스타일의 다차원 집계 기능
- 첫행기준 경우의수 출력
# 시간(신규 Date컬럼)과 공간(Country)을 축으로 하는 롤업 생성
# 예상결과 : 모든날짜의 총합, 날짜별총합, 날짜별 국가별 총합
rolledUpDF = dfNonNull.rollup("Date", "Country").agg(sum("Quantity"))\
.selectExpr("Date","country", "`sum(Quantity)` as total_quantity")\
.orderBy("Date")
rolledUpDF.show()
rolledUpDF.where("country IS NULL").show() # 날짜별 총합
rolledUpDF.where("Date IS NULL").show() # 모든 날짜 총합 
- 둘다 null : 전체 합계
- country null : 해당 Date날짜의 합계
7.4.2 큐브(cube)
- 모든 경우의수 출력
dfNonNull.cube("Date","Country").agg(sum(col("Quantity")))\ .selectExpr("Date","country", "`sum(Quantity)` as total_quantity")\ .orderBy("Date")\ .show()

- 둘다 null : 전체 합계
- country null : 해당 Date날짜의 합계
- Date null : 해당 국가별 합계 (rollup과 차이점 )
7.4.3 그룹화 메타데이터
- 큐브 또는 롤업을 사용할 경우 grouping_id를 사용 할 수 있음
| 설명 | 예시 | |
| 3 | 총 수량 (a,b모두 null) | |
| 2 | cube(a,b)일때 b기준 ( a 가 null ) | |
| 1 | cube(a,b)일때 a기준 ( b 가 null ) | |
| 0 | 모든 조합 ( a,b 모두 null이 아님) |

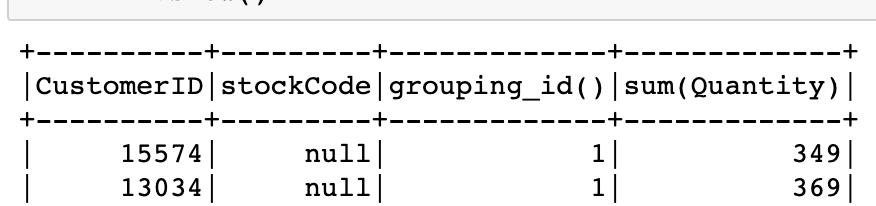

dfNonNull.cube("CustomerID","stockCode").agg(grouping_id(), sum(col("Quantity")))\
.orderBy(col("grouping_id()").desc())\
.show()7.4.4 피벗
- 로우를 컬럼으로 변환함.
- 피벗 연습용 DF 생성
pivoted = dfWithDate.groupBy("date").pivot("Country").sum()
Schema
root |-- date: date (nullable = true) |-- Australia_sum(Quantity): long (nullable = true) |-- Australia_sum(UnitPrice): double (nullable = true) |-- Australia_sum(CustomerID): long (nullable = true) |-- Austria_sum(Quantity): long (nullable = true) |-- Austria_sum(UnitPrice): double (nullable = true) |-- Austria_sum(CustomerID): long (nullable = true) |-- Bahrain_sum(Quantity): long (nullable = true) |-- Bahrain_sum(UnitPrice): double (nullable = true) |-- Bahrain_sum(CustomerID): long (nullable = true) |-- Belgium_sum(Quantity): long (nullable = true) |-- Belgium_sum(UnitPrice): double (nullable = true) |-- Belgium_sum(CustomerID): long (nullable = true) |-- Brazil_sum(Quantity): long (nullable = true) |-- Brazil_sum(UnitPrice): double (nullable = true) ...
7.5 사용자 정의 집계 함수
- scala 와 JAVA 에서만 가능
- 현재버전 사용가능한지 체크하기
7.6 정리
Uploaded by N2T